Accelerate FSDP
HuggingFace Accelerate
HuggingFace accelerate is a library that makes distributed training simple. It provides a simple API for launching training and evaluation jobs across multiple processes and machines.
Different from HuggingFace transformers Trainer or Lightning’s LightningModule, accelerate requires users to write their own training and evaluation loops.
Fully Sharded Data Parallelism
See PyTorch’s paper for more details about fully sharding.
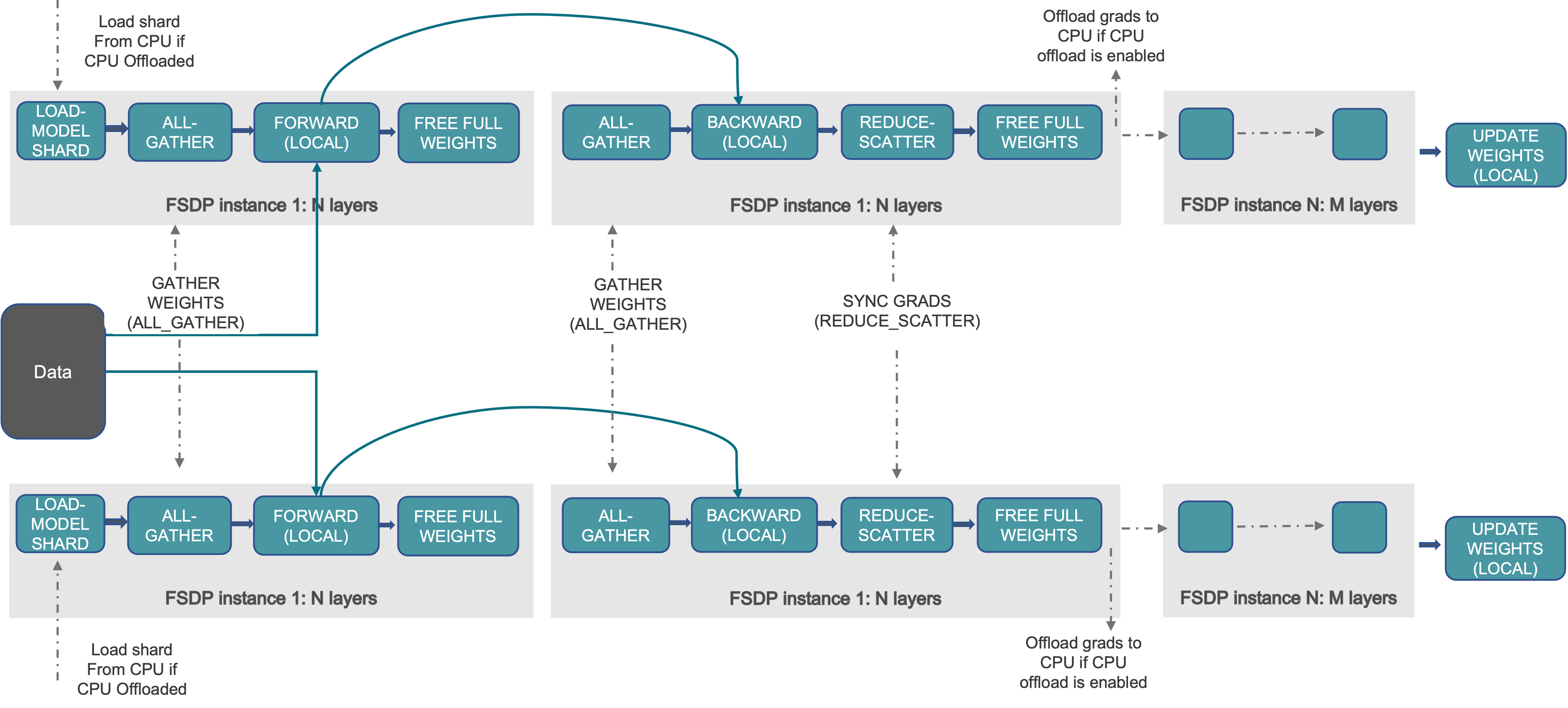
Accelerate’s Fully Shard Plugin
Accelerate’s fully shard plugin is a wrapper around PyTorch’s FullyShardedDataParallel module, providing a simple API for HuggingFace transformer models.
Here is an example of training a model with accelerate’s fully shard plugin.
cd mase-tools/machop/test/actions/accelerate_train
# launch training script using accelerate
accelerate launch --use_fsdp accelerate_fsdp.py
Note that if running the script without accelerate, i.e.,
python accelerate_fsdp.py
the script will only run on a single GPU.