Tutorial 1: Introduction to the Mase IR, MaseGraph and Torch FX passes#
In this tutorial, we’ll see how to import a model into Mase by generating a compute graph using the MaseGraph API and how to start optimizing models using analysis and transform passes. First, we’ll import a pretrained model directly from HuggingFace Transformers. For this example, we’ll use Bert for sequence classification. You can read the Bert paper for information regarding the architecture.
We get a warning saying that some weights were not initialized, since only the weights in the decoder are pretrained and included in the HuggingFace Hub. When we use the AutoModelForSequenceClassification API, a classification head is added at the end of the model, with randomly initialized weights.
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("prajjwal1/bert-tiny")
print(model)
Generate an FX graph for the model#
To import a model into Mase, we need to generate a compute graph. In the Machine Learning community, there are several ways of capturing and representing a compute graph, such as ONNX, Torchscript, MLIR, TVM, etc. Mase relies on Torch FX, which has the following features and benefits:
High-level IR: unlike
LLVMorMLIR,FXoffers a high-level representation of the computation which enables fast optimizations.Pytorch native: every operator in the FX graph correlates to a Python object or callable, meaning we can transform and optimize the graph, then simply regenerate the Python code required to run it. Unlike ONNX, there is no requirement for a dedicated runtime: all you need is Python.
When you call MaseGraph(model), the MaseTracer class runs a forward pass of the model with Proxy objects instead of the regular Tensor objects. These Proxies record every operation performed on them, which is then used to generate the compute graph. The following cell generates the graph and generates a drawing of the result.
import os
import platform
# Add Homebrew path for macOS (Graphviz is typically in system PATH on Linux)
if platform.system() == 'Darwin': # macOS
homebrew_bin = '/opt/homebrew/bin' # ARM64 Mac
if not os.path.exists(homebrew_bin):
homebrew_bin = '/usr/local/bin' # Intel Mac
if os.path.exists(homebrew_bin):
os.environ['PATH'] = homebrew_bin + ':' + os.environ.get('PATH', '')
from chop import MaseGraph
mg = MaseGraph(model)
mg.draw("bert-base-uncased.svg")
There are 6 different types of nodes in an FX graph: placeholder, get_attr, call_function, call_module, call_method, output. Each node has several associated attributes, such as name, args/kwargs and target. These have different contents and meaning depending on the node type. We provide a summary below, but for more details, see the FX documentation.
placeholder: represents a function input, which can be a
Tensoror another Python object.get_attr: retrieves a parameter from the Pytorch module hierarchy.
targetis the fully-qualified string name of the parameter’s position in the module hierarchy.call_function: applies a free function to some values.
targetis a handle to the Python callable.argsandkwargsrepresent the arguments to the function, following the Python calling convention.call_module: applies a module in the module hierarchy’s
forward()method with the given arguments.targetis the fully-qualified string name of the module in the module hierarchy to call.call_method: calls a method on a value.
targetis the string name of the method to apply to the self argument.output: contains the output of the traced function in its args[0] attribute. This corresponds to the
returnstatement in the Graph printout.
You may be wondering the difference between call_function, call_method and call_module nodes: call_function nodes can have arbitrary Python callable as targets, while the target for call_method nodes must be a Tensor class method. call_module nodes refer to torch.nn.Module objects which must be included in the Pytorch module hierarchy. For example, the Pytorch ReLU activation function can be seen any of these node types:
import torch
random_tensor = torch.randn(2, 2)
function_relu = torch.relu(random_tensor)
method_relu = random_tensor.relu()
module_relu = torch.nn.ReLU()(random_tensor)
assert torch.equal(function_relu, method_relu)
assert torch.equal(function_relu, module_relu)
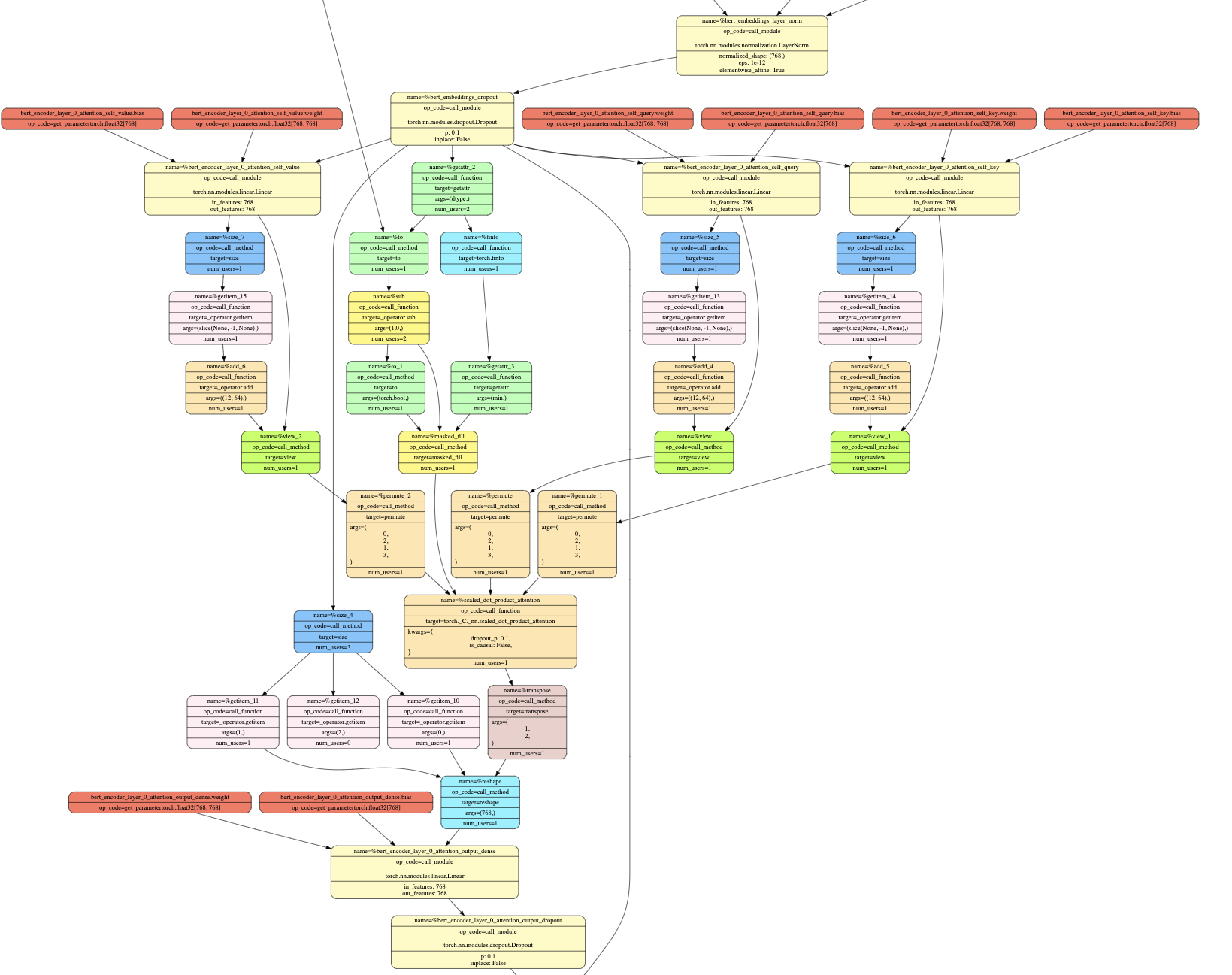
Open the generated SVG file (you may find this VSCode extension useful) and inspect each node. If you can’t generate the image, we show below a segment of the graph that corresponds to the first attention layer of the Bert encoder. If you also inspect the Bert implementation in the HuggingFace repository, you can see how each node in the generated graph corresponds to lines in the Python code. For example, the bert_encoder_layer_0_attention_self_<query/key/value> nodes correspond to the calls to the Query/Key/Value linear layers defined in the BertSelfAttention class. You can also see how not every piece of code has an associated node in the graph - when the code is being symbolically traced, parts of the code that aren’t executed (for example, if statements which never yield True) don’t interact with the Proxy objects, hence they’re not included in the graph.
{kind=link}
Understanding the Mase IR#
As previously mentioned, the Mase IR is built on top of Torch FX. However, the FX operator associated with each node in the graph refers broadly to Python semantics, such as how to execute code generation for a transformed graph. For example, when the FX code generator encounters a call_function node, it would know to generate code equivalent to node.target(*node.args, **node.kwargs), while for call_method nodes, the code would correspond to getattr(node.args[0], node.target)(*args[1:], **kwargs). However, beyond code generation, the FX IR has no information regarding the workload being executed by the graph - that’s where the Mase IR comes in.
As described in previous publications, the major benefit of the Mase IR is in offering a common abstraction layer for both hardware and software workloads (see here, here). You can find a list of Mase operators under the IR definition file. You can see that most operators correspond strongly with either Pytorch or ONNX operators. Each operator is also associated with a node type, which can be one of the following.
module_related_func: includes functions undertorch.nn.functionaland thetorch.nn.Modulethat wraps them. For example,torch.nn.functional.reluandtorch.nn.ReLUboth fall under this category.module: a MASE module is a subclass oftorch.nn.Modulethat does not have correspondingtorch.nn.functionalcounterpart. For example,torch.nn.BatchNorm2Dis a MASE module becausetorch.nn.functional.batch_norm_2ddoes not exist.builtin_func: MASE builtin_func includes functions undertorchthat are nottorch.nn.functionalandtorch.nn.Module, such astorch.catandtorch.bmm.
The following types are also present, which have the same meaning as in Torch FX.
placeholder: input node of a MASEGraph.get_attr: represents the attribute of a MASE module.output: equivalent to the return statement in the forward function.
Understanding the Pass System#
If you have worked with compilers, you might be familiar with the concept of a pass, which is a function that iterates over each node in the graph to perform some task. In Mase, there are two categories of passes: analysis and transform passes.
Analysis passes: extract some information about each node, annotate nodes with relevant data, and generate payloads to be used by subsequent passes.
Transform passes: change the topology of the graph by inserting, removing or replacing nodes.
All passes, whether analysis or transform, have the following structure. Every pass accepts a dictionary pass_args containing required arguments, and outputs a tuple of the output graph (which can be annotated or transformed) and a pass_outputs dictionary. A pass doesn’t need to use any arguments or generate any outputs (other than the output graph), however the argument and return signatures must follow this standard such that passes can be chained together.
def dummy_pass(mg, pass_args={}):
# ... do some setup
pass_outputs = {}
for node in mg.fx_graph.nodes:
# ... do stuff
return mg, pass_outputs
Next, we’ll show how to run some analysis passes required to raise the generated FX graph to the Mase IR. Then, we’ll come back to see how to write some simple analysis passes to do useful things.
Raising the FX graph to the Mase IR#
To convert the simple FX graph we generated into the Mase IR, we must run the following analysis passes, which annotate each node with relevant metadata. Note that metadata follows under three categories: common, hardware and software. Hardware metadata is used for generating FPGA accelerators in the emit Verilog toolflow (see Lab 4), while software metadata is used by passes such as autosharding, which automatically finds a model parallelism configuration in a GPU cluster. Common metadata is generally required by all workflows in Mase.
init_metadata_analysis_pass: initializes a
MaseMetadataobject for each node in the graph, which behaves like a dictionary and is stored undernode.meta["mase"]. Each metadata instance has the following structure, which is empty at initialization. See here for details on the implementation.
node.meta["mase"] = {
"common": {},
"hardware": {},
"software": {},
}
add_common_metadata_analysis_pass: populates the
node.meta["mase"]["common"]dictionary by executing the following two steps. See here for details on the implementation.Operator inference: determine the operator associated with each node in the graph from its fx operator and target, and annotate under
node.meta["mase"]["common"]["mase_op"]Shape Propagation: similarly to the Interpreter Pattern in the FX documentation, this involves running a forward pass of the entire model with a provided dummy input, and observing the Tensor metadata (shape, data type, stride, etc) of each argument and result for every node in the graph. This is then annotated under
node.meta["mase"]["common"]["args"]andnode.meta["mase"]["common"]["results"].
The add_common_metadata_analysis_pass requires a dummy Tensor input to run the shape propagation step. In the following cell, we show how this can be done using the HuggingFace tokenizer, to which we pass two truthful statements.
import torch
import chop.passes as passes
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
dummy_input = tokenizer(
[
"AI may take over the world one day",
"This is why you should learn ADLS",
],
return_tensors="pt",
)
mg, _ = passes.init_metadata_analysis_pass(mg)
mg, _ = passes.add_common_metadata_analysis_pass(
mg,
pass_args={
"dummy_in": dummy_input,
"add_value": False,
},
)
Example: writing an analysis pass#
Writing an analysis pass is often simple - in the following example, we implement a pass which counts the number of dropout layers in the graph. We also show how to use the get_logger API from chop.tools to provide information about the graph to the user at runtime.
from chop.tools import get_logger
logger = get_logger("mase_logger")
logger.setLevel("INFO")
def count_dropout_analysis_pass(mg, pass_args={}):
dropout_modules = 0
dropout_functions = 0
for node in mg.fx_graph.nodes:
if node.op == "call_module" and "dropout" in node.target:
logger.info(f"Found dropout module: {node.target}")
dropout_modules += 1
else:
logger.debug(f"Skipping node: {node.target}")
return mg, {"dropout_count": dropout_modules + dropout_functions}
mg, pass_out = count_dropout_analysis_pass(mg)
logger.info(f"Dropout count is: {pass_out['dropout_count']}")
Example: writing a transform pass#
In this example, we delete all dropout nodes from the graph. Dropout is a useful training technique, but it doesn’t have any effect on the activations at inference time, hence these nodes can be removed to simplify the graph. Transform passes may involve deleting, inserting, or replacing nodes in the graph. When doing this, we must carefully handle the arguments to ensure the graph topology is valid after transformation. Before erasing the dropout nodes, we must first find all other nodes that take the output of the dropout node as arguments, by running node.replace_all_uses_with. Without doing this, there would still be nodes that require arguments that no longer exist.
Task: Delete the call to
replace_all_uses_withto verify that FX will report a RuntimeError.
Finally, we rerun the analysis pass previously implemented to recount the number of dropout modules, and verify this is now zero.
import torch.fx as fx
def remove_dropout_transform_pass(mg, pass_args={}):
for node in mg.fx_graph.nodes:
if node.op == "call_module" and "dropout" in node.target:
logger.info(f"Removing dropout module: {node.target}")
# Replace all users of the dropout node with its parent node
parent_node = node.args[0]
logger.debug(f"This dropout module has parent node: {parent_node}")
node.replace_all_uses_with(parent_node)
# Erase the dropout node
mg.fx_graph.erase_node(node)
else:
logger.debug(f"Skipping node: {node.target}")
return mg, {}
mg, _ = remove_dropout_transform_pass(mg)
mg, pass_out = count_dropout_analysis_pass(mg)
assert pass_out["dropout_count"] == 0
Exporting the MaseGraph#
You can export the transformed MaseGraph to be shared and used in future tutorials, by running the mg.export() command.
from pathlib import Path
mg.export(f"{Path.home()}/tutorial_1")
After exporting, you can pick up where you left off by running the MaseGraph.from_checkpoint constructor.
new_mg = MaseGraph.from_checkpoint(f"{Path.home()}/tutorial_1")